
Lately I have been spending my free time working on a mobile application for car enthusiasts – DrivnBye. This application has forced me out of my comfort zone with every feature I work on. We’re a couple months from release on the iOS and Android app store and we decided to start stress testing our backend, an express server utilizing graphQL and a postgres database and it looks like our geospatial queries are quite slow; almost half a second slow.
For some context, you can think of this app similar to google maps or zillow. The main landing page isnt a conventional scrollable social media layout like you’re used to; instead it’s a map view where you can view posts, events, businesses and more on a map. In the same way zillow and google maps allow you to the travel the world, you’re able to travel to other countries to see posts there. In this blog post we’re just going to focus on the “posts” table in our database.
When testing the app we only created 200 fake rows in the database. Enough to test features but not enough to spot inefficient queries or functionality that needs optimization. We ran a new script that generated over 2,000,000 fake posts in our database and it was clear, the queries that loaded these markers in the map was slow and took well over 2 seconds to return anything.
Luckily for me, I started reading the Design Interview Volume 2 book since it focused a lot on proximity and geospatial system design questions. The very first question related back to my application very closely and they called my original query “naive and inefficient”. And after testing, they were right; this query is slow.
What is Geohashing
Before we jump into how I increased the performance by 100x of my original query I do want to give some background on what geohashing is and how we can implement it.
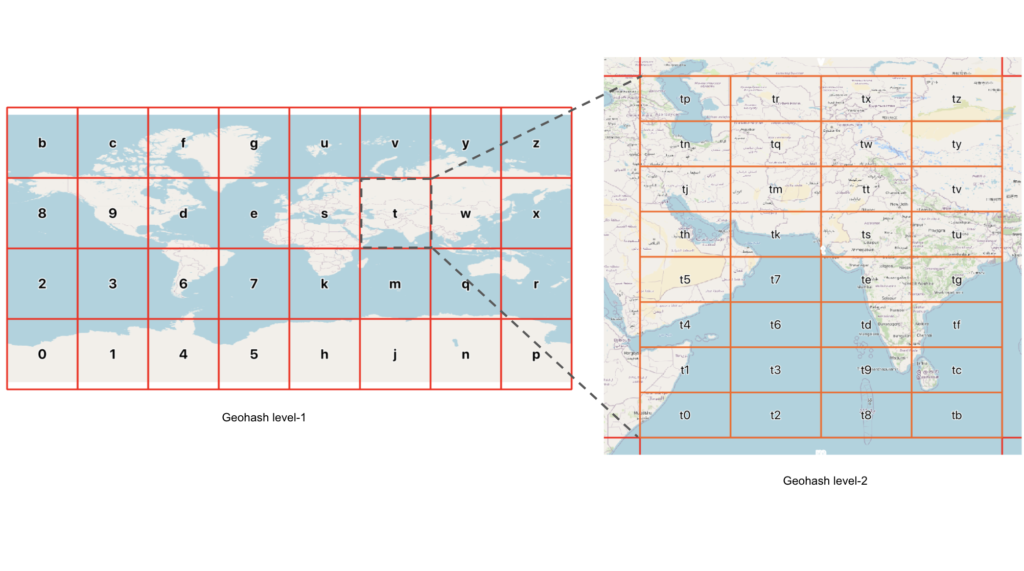
Geohashing is a method of encoding geographic coordinates into a short string of letters and digits. The idea is to create a unique identifier for a specific location on the Earth’s surface by applying a hashing algorithm to its latitude and longitude. This allows for the representation of geographic locations in a concise and easily shareable format.
The process of geohashing involves dividing the world into a grid and assigning a unique code to each cell in the grid. The precision of the geohash depends on the length of the generated code – shorter codes represent larger areas, while longer codes pinpoint smaller regions with greater accuracy.
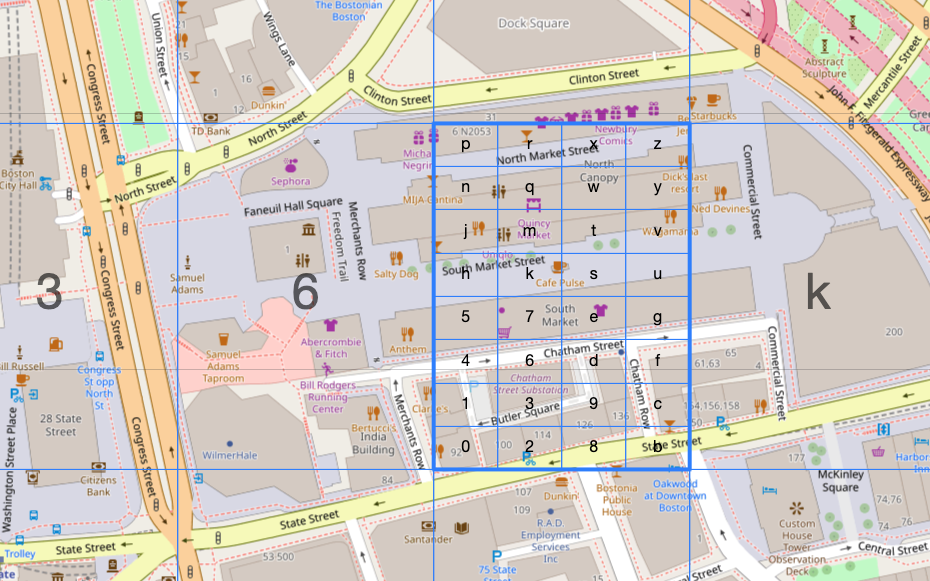
Let’s think of an example, say I want to locate Faneuil Hall in Boston, MA. As you can see the more we zoom into Faneuil hall the more precise we can get. The smallest geohash that contains all of Faneuil Hall is drt2zp, but that geohash contains a lot more than just Faneuil Hall. We can get more precise by going from 6 levels of precision to 7. The following geohashes now contain Faneuil Hall: drt2zp3, drt2zp6, drt2zp7, drt2zpk.
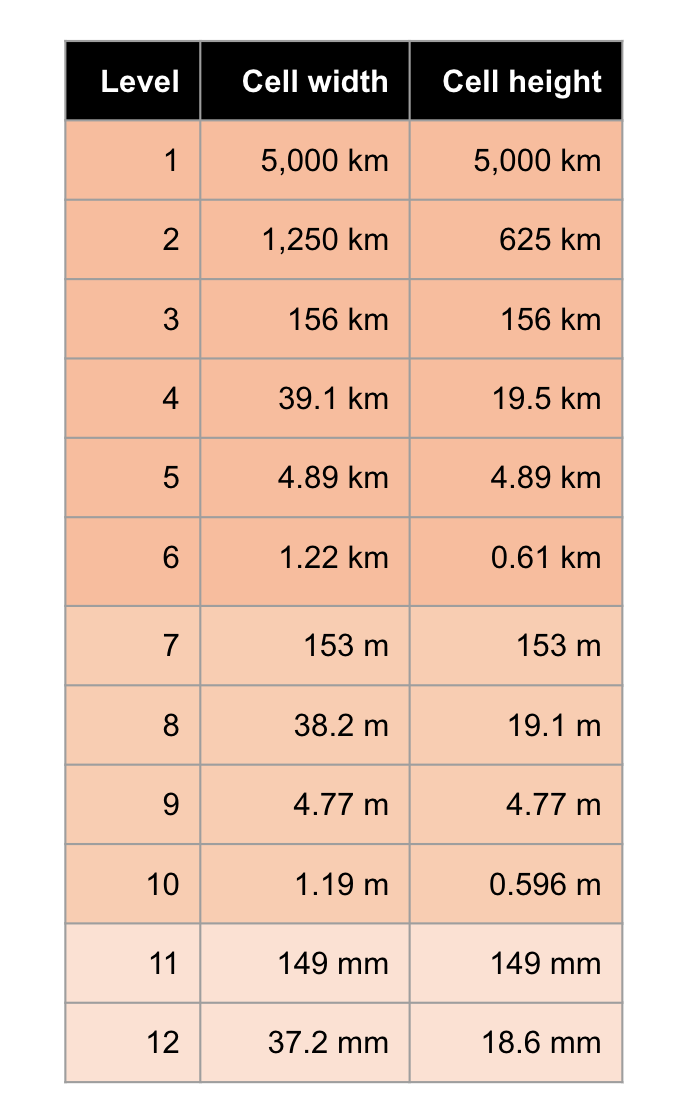
This pattern can repeat up to 12 layers of precision where it is +- 37mm x +-18.6mm. That is quite precise for a single string.
Back to the Backend
How does this all relate to making an SQL query quicker? Now we get to dive into the original SQL query and why it was so slow.
SELECT
id
FROM
"Post" AS p
WHERE
p.latitude BETWEEN 42.032592 AND 42.67398
AND
p.longitude BETWEEN -71.728091 AND -70.771656;
LIMIT 100This query was simple, easy to read, and most importantly, it worked which is why it took us weeks to realize this query was slow and needed to be replaced.
Before we dive into how we made it quicker we have to understand the system requirements for this switch.
- Our frontend requires latitude and longitude values in order to precisely plot each marker
- Make no change to the client side, all changes must be within the backend repository
- There should be minimal spill over (markers rendered outside of the viewable area of the map)
- Requesting 200 rows should take under 10ms.
- Focus on optimizing the SQL query, not the actual graphQL endpoint.
- Allow the user to zoom out to view the entire state of Texas or zoom into to focus on a singular town or city
With everything in mind we have a single query that is taking a noticeable amount of time loading markers in a given area and we chose to implement geohashing to solve this slow down.
Hybrid approach
Since the user is able to view entire states or a singular city we need to keep in mind the area they are viewing. We don’t want to use geohash with too high of a precision when they are zoomed out; on the other hand we also don’t want to use a geohash with too low of a precision when viewing a small area since that would mean there would be quite a lot of spill over.
The graphQL endpoint receives 4 arguments, a minimum and maximum value for latitude and longitude. We then use a library called ngeohash to ask for the geohashes of precision 3 and precision 4 given the “bbox” that we received from the graphQL endpoint.
const geohash3 = geohash.bboxes(minLat, minLong, maxLat, maxLong, 3);
const geohash4 = geohash.bboxes(minLat, minLong, maxLat, maxLong, 4);We also have a constant that defines when a user is zoomed in enough to switch from using the precision 3 to the precision 4 geohash.
For the sake of this article we will be focusing on geohashes with a precision of 3. Taking our SQL query and cutting it down to what is appropriate for this comparison is this:
SELECT
id
FROM
"Post"
WHERE
"geohash3" IN ( 'drk', 'drm', 'drs', 'drt' )
LIMIT 100;This query is asking for the same area as the original query with some spill over; so technically a larger area than the original query.
Benchmarking
Disclaimer: I am not a SQL wizard and still learning every day about SQL so this section might seem brief. I encourage you to test this out by yourself.
Constants
To keep this comparison fair, we are going to outline constants that will not change from test to test.
- DB Rows: 2,000,000
- “geohash3” or “latitude” and “longitude” will be indexes on this table during the test
- All Cacheing and buffers are disabled/ cleared after each execution
- SQL Script is executed with dbVisualizer SQL Commander
- Limited to 100 rows then 1,000 rows.
Original
100 rows: 34ms
1,000 rows: 452ms
Geohash3
100 rows: 3.8ms
1,000 rows: 12.45ms
That is a 88% improvement for 100 rows and a 97.24% improvement for 1,000 rows! How noticeable is that in the app? Unless you’re looking for it, i dont believe anyone would notice when querying 100 rows which is what we are normally doing, but this kind of improvement allows our backend to operate efficiently while having multiple clients connect to it. An improvement of 88% allows us to worry less about needing to increase hardware or number of nodes in the future during peak hours; we do foresee needing to scale up or scale out during peak hours but an improvement like this lessons the headroom required.
Why?
I am going to be paraphrasing the “System Design Interview Volume 2” explanation because I believe they do a better job explaining why the original query is so slow.
SELECT
id
FROM
"Post" AS p
WHERE
--- dataset 1
p.latitude BETWEEN 42.032592 AND 42.67398
AND
--- dataset 2
p.longitude BETWEEN -71.728091 AND -70.771656;
LIMIT 100Even with indexes on latitude and longitude the performance would not increase all too much that is due to two reasons.
1. Intersection and Inequality Queries
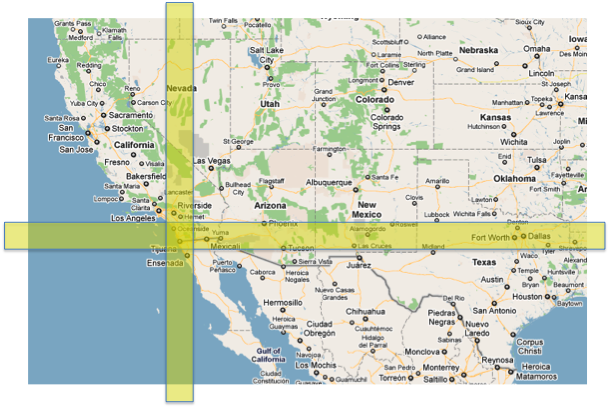
The way this query executes is by looking for dataset 1 and dataset 2, then performing an intersection to determine which points in dataset 1 also fit the criteria for dataset 2. Thanks to indexes on latitude and longitude we’re able to query these values but that does not help us query the intersection between dataset 1 and dataset 2.
We also need to consider how large the queries are in each dataset. In dataset 1 we’re looking for all posts that are between each latiude; that includes points very clearly outside of dataset 2. This principal applies both ways causing a bunch of rows thrown away when performing the intersection.
Using something like geohashing we don’t have to worry about intersections or throwing rows away due to it not satisfying a second dimension. In our implementation we’re matching exact matches instead of looking for shared prefixes which means we’re searching for indexes for a direct match.
2. Indexing multiple dimensions
Indexes help with search speed in one dimension, so naturally you want to ask – how can we represent a precise location in a single dimension?
Entering Geohashing
Geohashing allows you to represent a row’s precise location in a simple 12 character string. After setting the geohash in the database as an index you can now perform queries like the ones below.
SELECT
id
FROM
"Post"
WHERE
"geohash3" IN ( 'drk', 'drm', 'drs', 'drt' );
--- OR Using "LIKE" to match all hashes that share a prefix
SELECT
id
FROM
"Post"
WHERE
"geohash12" LIKE "9rk%";Conclusion
If you’ve made it this far hopefully you’ve learned a thing or two about geospatial queries and want to learn more! I am hoping I can make more blogs like this in the future when we run into these kinds of problems. Deploying this backend change to our staging environment with 10 people all with graphiQL open spamming the query button or running a curl request in a loop we noticed a massive difference in hardware utilization, response times, and database rows read. So much so we were not able to trick our load balancer into thinking it needed to scale.
Leave a Reply